TL;DR#
In this post I’m going to share a Pragmatic Layered Architecture that I’m following on most of my projects. This is a battle-tested approach that I’ve been practicing and polishing for years now (and still learning). It embodies some principles from Clean or Hexagonal Architecture with strong focus on practical aspects but not purity or dogma.
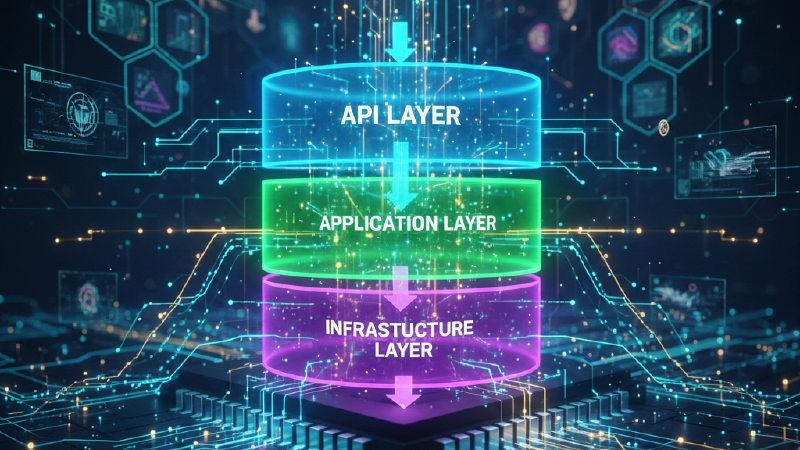
The concept in a nutshell:
- Three-layer structure: API → Application → Infrastructure.
- Dependencies (imports) flow inward towards the app (reminds hexagonal). Will explain later why this I follow this.
- Application layer - application logic lives here. Defines types and interfaces for infrastructure.
- Minimal mapper tax: Minimal mapping/enforcement. Will explain later where and why.
- Infrastructure is a tiny Anti Corruption Layer with little to no logic, just database calls or external interactions.
These principles work in any language—whether you’re building. I will later share an example boilerplate repo written in Go with all the concepts demonstrated, however I’ve applied same principles in TypeScript and Java, of course keeping in mind language idioms, but the core ideas remain the same.
Dogmatic Architecture Problem#
Most architecture types such as hexagonal, onion or clean architecture tell you to build abstractions, keep strict boundaries and isolate the domain. The domain must be pure, independent from frameworks, databases, and external systems.
However the reality is more nuanced. It is very uncommon to switch databases, cloud providers or other third party systems on a real world projects. Sure, sometimes your project must support polymorphic environments, but most of the time you pick a database and stick with it for years. And if you have to migrate, usually the coding part is the smallest chunk of the work. Data migration, testing, deployment, cutover planning are way more complex and time consuming.
I’m not saying that abstractions are completely useless, the question is how much abstraction is enough? Where to draw the line between purity and pragmatism?
Let’s consider two extremes:
Follow architecture diagrams religiously → 12 files to save a user.
UserDTO,UserDomain,UserEntity,UserDAO…. (you got the idea). Mappers everywhere. Pass-through code is common. Understanding the flow requires keeping this all in mind. Onboarding is slow, cognitive load is high. Well AI will probably be happy with this (and AI vendors as well while you’re burning tokens), but humans struggle.Start too simple → No layers, flat structure, three months in, and testing becomes a nightmare. All tests are integration. Covering simple edge case requires spinning up entire stack. Flakiness is a norm, you are retrying tests constantly. Making any change is risky because you can’t be sure what will break. AI also struggles because there is no clear structure.
In this article I will show you how I balance these two extremes, keeping testability from day one, enforcing boundaries where it’s most valuable, softening rules where it makes sense. Generally keeping the code comprehensible for both humans and AI.
The Three Layers#
Let’s start from the layers. The three layers are: API Layer, Application Layer, Infrastructure Layer. I’ll talk about each in detail later, but here’s the high level overview:

Important thing here is the “call flow” versus the dependencies flow. The call flow (uses arrows) is obviously from top (API) to bottom (Infra)—nothing special there. But the dependencies flow (the imports, the “depends on” arrows) goes inward toward the application layer.
Why dependencies flow inward:
Clear ownership of requirements: When the application layer defines
UserRepositoryinterface, you see exactly what the business logic needs from infrastructure. The application is in control. I do not attempt to abstract away the infrastructure layer too much (at least not by default). Just define the interface with methods you need, keeping your infrastructure capabilities in mind.Prevents circular dependencies: Inward flow naturally eliminates import cycles. API and Infrastructure both depend on Application, but never on each other. Depending on your language, this issue may be less of a pain, but it works very well in Go. TypeScript strictly speaking allows circular dependencies, but as for me this is a code smell and I would rather avoid it.
Incremental refactoring option: If you later need stricter boundaries or full hexagonal architecture, the foundation exists. But unlike dogmatic approaches, you’re not paying the abstraction tax upfront—you’re just following a dependency direction that makes testing easier today.
The Application Layer#
The application layer contains all business logic and defines the data structures and all the infrastructure that it needs. I prefer to split commands and queries into separate components, which is CQRS pattern. But don’t picture full blown CQRS with event sourcing and other stuff here, it’s just a separation of reading and mutating parts of your application logic. Let’s discuss why.

Commands: Where Business Logic Lives#
Commands handle state mutations. Usually things like validation, business rules, transactions and similar kind of stuff is happening here. This is usually the most logic heavy part of your system.
Because of this complexity, this part is way more practical to be unit tested with mocked out dependencies.
Queries: Reading Layer#
Queries handle data retrieval. In many applications, reads are way more common than writes (think 90% reads, 10% writes or even less). In most typical cases queries are translating to database SELECTs (or any other query language your DB has) and then fetching the results. Because of this, I prefer to integration test queries directly against the real database.
Direct SQL on Application Layer for Queries#
You may define all your queries on infrastructure layer as well, but this very often leads to a “pass-through” code like this:
type UserQueries struct {
repo UserRepository // Infrastructure layer interface
}
func (q *UserQueries) GetUserByEmail(ctx context.Context, email string) (*User, error) {
return q.repo.GetUserByEmail(ctx, email) // Just passes through
}This code adds no value, just boilerplate. Instead, I prefer to allow SQL queries on application layer. I’m not pretending that I might change the database later. And even if it happens, refactoring and moving this code on infrastructure layer is a mechanical task that AI can handle easily.
So here is how I do it:
type UserQueries struct {
// Tiny interface that allows running SQL
databaseQuerier Queryer
}
func (q *UserQueries) GetUserByEmail(ctx context.Context, email string) (*User, error) {
var user User
query := "SELECT id, name, email FROM users WHERE email = ?"
err := q.databaseQuerier.QueryRowContext(ctx, query, email).Scan(&user.ID, &user.Name, &user.Email)
return &user, err
}Then you spin up a real database connection in tests, write some test data to the DB, and verify that your queries work as expected. Just make sure to use a separate database for tests—this will make your life way easier :).
Reusable queries and pass-through#
One challenge with this approach is query reuse. This is the case where I move such queries to infrastructure layer and then use everywhere it needs to be used.
This, however, leads to potential pass-through code in case you also need to expose this query to the outside. So you may still end up with pass-through code like this:
type UserQueries struct {
repo UserRepository // Infrastructure layer interface
}
// GetUserByID is reused and exposed outside
func (q *UserQueries) GetUserByID(ctx context.Context, userID string) (*User, error) {
return q.repo.GetUserByID(ctx, userID) // Just passes through
}Some languages may allow you to slightly simplify this, for example in TypeScript you can just “re-expose” the method without defining a new one, something like this:
// Your repository
type UserRepository = {
getUserByID(userID: string): Promise<User | null>;
// other methods...
}
// Your queries exposing the same method
type UserQueries = {
getUserByID: UserRepository['getUserByID'];
};
function createUserQueries(repo: UserRepository): UserQueries {
return {
// just re-exposing the method
getUserByID: repo.getUserByID,
// other methods...
};
}Note: In TypeScript I prefer functional approach with composition. If you do classes, you may still be able to do it, but slightly differently (and maybe not as elegant). Strictly speaking in Go you can also do something similar with embedding, but it looks ugly and less readable as for me.
Pass-through alternative#
There is an alternative to this - allow repositories to be used from outside (e.g on API layer). Maybe it’s ok to do that, but I prefer not to, I prefer consistency in this regard - outside is only interacting with application via commands or queries. Though this thing stays open in my mind, we’re defining infrastructure on application layer so repositories are strictly speaking an application concept… Anyway not sure what’s the best here, so sticking to the original approach for now.

SQL Spread Across Layers#
One common question is “where should SQL live”? In this approach, SQL can live on both application and infrastructure layers. I’m ok with that. I’ll probably repeat myself, but database swap is a rare scenario, and pass-through is more annoying than having SQL in two layers. I think it’s important to agree on this with your team and be consistent. And this, BTW, is a good rule to add to an AGENTS.md file so AI also knows about it.
Infrastructure Layer#
The infrastructure layer holds implementations for all the application defined infrastructure interfaces. It’s the only layer that deals directly with databases, SQL, Pub/Sub, external APIs or anything else of this kind.
In Clean or Hexagonal architecture you may hear that application should be infrastructure agnostic, however I prefer to be pragmatic here. You’re spending hours picking particular database (usually Postgres :)), or researching if given Pub/Sub system fits your needs, and then what? abstract it away…? this sounds silly to me.
I prefer to think of this layer as a tiny ACL (Anti Corruption Layer) that allows you to keep your naming conventions, use stricter data types and things like that (e.g UUID vs string for IDs or Date in TypeScript). You may also want to move some serialization here as well. But other than that, this layer should be as thin as possible.
If you want ACID transactions on the application layer, just use them and there are number of techniques that allow you to do it in a more or less “clean” way. For example in Go I might define a Transactor (similar to Querier I mentioned before) and then have your repository methods require transaction context, for example:
type Tx
// Transactor allows DI and unit tests with mocks.
// It conforms to sql.DB
type Transactor interface {
BeginTx(ctx context.Context, opts *sql.TxOptions) (*sql.Tx, error)
}
type UserRepository interface {
// CreateUser supports transactional context
CreateUser(ctx context.Context, tx *sql.Tx, user User) error
// other methods...
}
// Then your service or command handler would look like this:
func (s *UserService) RegisterUser(ctx context.Context, req RegisterUserRequest) error {
tx, err := s.Transactor.BeginTx(ctx, nil)
if err != nil {
return err
}
defer tx.Rollback()
err = s.userRepo.CreateUser(ctx, tx, User{...})
if err != nil {
return fmt.Errorf("failed to create user: %w", err
}
// do other transactional work...
return tx.Commit()
}In other languages you might follow similar patterns, however the concept stays the same - interfaces for dependency inversion but not for “abstracting away”.
In Go specifically this “vanilla” Transactor pattern may look a bit verbose, and if your app is doing a lot of transactions, you may want to go a bit further and define your Transactor for example like this:
type Transactor interface {
// ExecInTransaction executes the given function within a transaction
ExecInTransaction(ctx context.Context, fn func(tx *sql.Tx) error) error
}
// then you would do something like below:
func (s *UserService) RegisterUser(ctx context.Context, req RegisterUserRequest) error {
return s.transactor.ExecInTransaction(ctx, func(tx *sql.Tx) error {
err := s.userRepo.CreateUser(ctx, tx, User{...})
if err != nil {
return fmt.Errorf("failed to create user: %w", err
}
// do other transactional work...
})
}Generally there are multiple ways to deal with that, just use what fits your language and style best.
One more thing to mention though is that I don’t create separate types on the infrastructure layer by default and reuse what application layer defines as much as possible. Extending application types with some extra fields that are infrastructure-specific is ok most of the time. As complexity increases, separate data types might be introduced, but it’s not a default that I tend to follow.
API Layer#
And finally the API layer. As it’s name suggest - it is handling protocol concerns—HTTP, gRPC, GraphQL, message queues, whatever your application exposes or consumes. It’s the boundary between the outside world and your application logic.
Conceptually even CLI interface to your app fits here. However with CLI specifically I prefer to soften the rules even further. By default - attempt to keep CLI following same rules as other API types (e.g use commands or queries from app). However sometimes there are practical reasons to bend the rules a bit - for example if you have a maintenance CLI command that does some direct database operation for emergency purposes, it’s ok to do it directly from CLI layer. Just make sure this is an exception, not a rule.
One more thing about CLI, when running them, best to run them in actual environment, but not from your local laptop with configured prod credentials. There are multiple ways of doing that, few things I did in the past that worked for me:
- In GCP - Cloud Run jobs - you can run a ad-hoc jobs right from the Cloud Console with parameter overrides
- In K8S + ArgoCD - Argo has Workflows that conceptually are similar to Cloud Run jobs
And of course, this is not a “hard” rule for CLI. There may be cases where the “sky is falling” and you need to run something from your laptop right now. Depending on your risk tolerance and situation, you may allow that as well.
The Mapper Tax
Remember I mentioned about mapper tax and where I’m forcing to pay it. So the API layer is the this place.
Let me show you a few examples that I’ve seen happen many times in real-world projects.
Firstly, some from the Go world:
type User struct {
ID string `json:"id"`
Name string `json:"name"`
Email string `json:"email"`
PasswordHash string `json:"-"` // should not be exposed
}If you are sharing this User with your API layer and then just using json.Marshal to serialize it, what happens if someone forgets to add the json:"-" tag to the PasswordHash field? You just leaked password hashes to the outside world. Not good… I’ve seen this particular case stay unnoticed for months in a production system.
Similar thing may happen in TypeScript. Let’s consider some NestJS controller example:
// Let's say you have this User entity on application layer
type User = {
id: string;
name: string;
email: string;
passwordHash: string; // should not be exposed
};
// Then you declare your user DTO for API layer (I'll skip annotations for brevity)
class UserDTO {
id: string;
name: string;
email: string;
}
// So far so good, no password hash is exposed, but let's see what's typically happening on controller
class UserController {
@Get('/users/:id')
async getUser(@Param('id') id: string): Promise<UserDTO> {
const user = await this.userService.getUserByID(id);
// User and UserDTO are type compatible, so this works,
// but leaks passwordHash to the response...
return user;
}
}There are multiple ways to solve it. Typically in Go I would just do an explicit mapper function. In NestJS you may do the same, or use class-transformer approach. Just keep this in mind and instruct your AI agent to follow this rule as well.
Maintainability is what matters#
Over the years, I realized that following any patterns or book advice with extreme dogmatism is a trap. Balancing complexity and your actual needs is the key. It’s not really about layers—it’s about where complexity lives and what abstractions you actually need right now.
A good sign that your system is well architected and maintainable is when:
- You’re adding new features without fighting the structure
- You have good unit test coverage (100%? probably no, but 80-90% is a good target) and tests are fast and reliable. You follow test pyramid principles (most tests are units, some integration, few end-to-end).
- CI/CD pipeline is fast and reliable.
- Different components and parts of the system are loosely coupled and easy to understand
- Production incidents are rare and when they happen, they’re easy to debug and fix.
In my early career years, I used to write integration tests most of the time, usually spinning up databases or doing complex network mocking (with Wiremock or similar tooling). “It tests the real thing!” I thought. Sure, it kind of did. It also took 20 minutes to run the test suite. Attempting to test edge cases often meant adding a monstrous setup just to get the data into the right shape. And don’t even get me started on flakiness….
Now I think it’s the other way around. A big part of my tests are units. Sure I have integration tests, but they’re now more isolated, focused, and faster. Most of my e2e tests are smoke or critical path tests. And this is exactly how this architecture emerged. Pain and struggle lead to it, and I use theoretical concepts as a guide but not a strict rule.
Here’s the interesting part I noticed over time: If you practice TDD, this kind of architecture happens naturally (well, maybe with different layers or names of things). You start with a test, realize you need to mock something, and define an interface. As you add more tests, you separate concerns, and the layers or components emerge organically. TDD doesn’t force you into this architecture—it guides you toward it because it’s the path of least resistance for testable code.
And it doesn’t really matter if you use AI or not. AI helps to generate the code, but you control the architecture, you define goals and outcomes. And it will be you who will maintain the system, well at least until we finally reach AGI :).
When to Skip This Architecture#
There are cases where I would probably skip this entire structure and do something simpler:
Simple CRUD APIs: If your service is purely CRUD with no business logic, you might not need an app layer at all. API → Repository is fine. Though honestly, most “simple CRUD” projects that I’ve built grow to include business logic within weeks.
CLI tools: Well if it’s going to be something very complex then probably, but very likely you can keep things simpler.
If nanoseconds matter: If you’re building something that needs every bit of performance, you probably want to drop all the layers and overhead. However, for most business apps I build (including high-load ones), I’ve never seen a noticeable performance impact caused by layers.
A Side Benefit I Didn’t Expect: AI Gets It#
I found that AI coding agents understand well structured codebase very well (with some hints, of course). Just describe the architecture briefly in AGENTS.md or ARCHITECTURE.md, and AI follows it, especially if there are examples.
Final Thoughts#
I’ve been practicing this architecture for years, and here’s what I keep coming back to: architecture should optimize for the problems you actually have, or at least see on the horizon, not the ones you might have someday.
Will you swap databases? Probably not. Will you be adding new features or extending existing ones? Very likely yes. Will you need to test your business logic without spinning up Postgres? Absolutely. Do you want your teammates to get up to speed quickly? Of course.
This architecture solves those problems. Not perfectly—nothing does—but well enough that I can focus on building features instead of fighting my own structure.
If you’re building a new backend service, don’t start with a flat structure “because it’s simple.” That simplicity is a trap. But also don’t start with 12 files per domain entity “because Clean Architecture says so.”
You can always add more abstraction later, but it’s usually much harder to remove it once it’s there.
Oh, and I almost forgot—I have a Go boilerplate repo that demonstrates all these concepts in practice. Check it out here: Golang Backend Boilerplate.
Further Reading#
- Clean Architecture by Robert C. Martin - The foundational principles. Quite old but still relevant.
- Hexagonal Architecture - Ports and adapters pattern
- Domain-Driven Design - Strategic design patterns
- The Twelve-Factor App - Best practices for modern backend services
This post explores architectural principles from a YouTube video where I discuss my backend boilerplate template.
